There is also a big, and growing number of recipes working with the most widely used speech databases. My problem was, however that I am not an academic, but just a coder that likes to play from time to time, with technologies that look interesting and promising. I wanted to get an idea how Kaldi works, but I don't have access to these expensive datasets. That's why I have started to search for a way to use a publicly available database. The best option I have found so far is a subset of RM1 dataset, freely available from CMU. In fact the data only includes pre-extracted feature vectors, and not the original audio. The details of feature extraction in Sphinx are almost certainly different from that in Kaldi, but as long the features used in training and decoding match we should be OK. Kaldi already has a recipe for RM, so modifiying it to use CMU's subset was a rather trivial excercise. This post describes how to use this modified recipe in case other people want to try it.
Update: As of Feb 27, 2012 a slightly modified version of this recipe is part of the official Kaldi distribution.
Setup Kaldi
This tutorial will assume that you still don't have Kaldi installed and you are using GNU/Linux OS. First of all we need to obtain the toolkits' source code:
svn co https://kaldi.svn.sourceforge.net/svnroot/kaldi/trunk@762 kaldiI am explicitly using revision 762 here, simply because this is the version of Kaldi I have tested my recipe against. Then the recipe itself can be obtained from GitHub or BitBucket (I really like their free private Git repos).
git clone git://github.com/vdp/kaldi-rm1-mod.git OR git clone git@bitbucket.org:vdp/kaldi-rm1-mod.gitThe recipe assumes that it is stored in a sibling directory of the directory which contains Kaldi. Kaldi needs to be patched in order to add some tools, that I wrote:
cd kaldi patch -p1 < ../kaldi-rm1-mod/cxx/diff-r762.patchOnly one of these tools is essential, and the others are only used to visualize some data structures. I will say more about this later. Kaldi then can be built in the usual way (just follow the INSTALL file).
Setup RM1 data
Download the cepstra files from CMU's site and extract the archive:
tar xf rm1_cepstra.tar.gz mv rm1 rm1_featsThen you will need to download some metadata from LDC's website:
wget -mk --no-parent -r -c -v -nH http://www.ldc.upenn.edu/Catalog/docs/LDC93S3B/ mv Catalog/docs/LDC93S3B ./ rm -rf CatalogThe files that we need are stored under LDC93S3B/disc_1/doc/ directory. The original Kaldi RM recipe uses a lexicon stored in a file called pcdsril.txt, but unfortunatelly it's not among the files distributed freely by LDC. Now, actually a quick web search reveals that it can be found in some researchers' home directories, but since I wasn't completely sure about its legal status I decided to use the dictionary that comes with CMU's data in the master branch of my recipe.
Running the recipe
The main script that drives the training and decoding is run.sh in the root directory of my recipe. The line below need to be changed so that RM1_ROOT to point the directory in which the CMU and LDC data is stored:
RM1_ROOT=/home/vassil/devel/speech/datasets/rm1The scripts assume that the aforementioned rm1_feats and LDC93S3B directories share a common root directory, and the variable $RM1_ROOT points to this directory. If kaldi and kaldi-rm1-mod are not siblings as explained above then you may also need to change the variable $root in path.sh to point to kaldi. When all of the above steps are done, you can cross your fingers and run:
./run.shThis may take an hour or two for the recipe scripts to go through a subset of the stages in the original recipe. The results of execution are stored in exp subdirectory. The acoustic models and HMM state tying trees are stored under exp/{mono,tri1,tri2a}, and the results of the test set decoding are in exp/decode_{mono,tri1,tri2a}. The word error rates for the different decoding stages can be seen in the wer files in their respective directories(e.g. exp/decode_mono/wer). The WER for the version of the recipe that uses CMU's dictionary is significantly higher. Probably it is at least partially due to the fact, that when preparing the dictionary my scripts blindly remove all pronunciation variants except for the first one. The WER when using the original dictionary was about 6 something %, and above 7% when CMU dictionary is used.
Extra tools (with some pictures)
As I already said there is only one extra tool that is needed for the recipe to run. It is called pack-sphinx-feats and its sole purpose is to convert the Sphinx feature files into Kaldi tables.
Because the WFST-based speech recognition is new to me I wrote some other tools to help me visualize the data structures used during the training and decoding, and also to get a basic idea of what programming Kaldi and OpenFST feels like. All these tools are just barely tested and should not be exptected to be particularly robust or bug-free. One of these is draw-ali. It has similar function to that of the Kaldi's tool show-alignments, but instead in text it shows the alignments as a distinctly colored trace through a GraphViz diagram. Initially I had assumed that the final training and decoding graphs are input-deterministic, so I had to rewrite this tool after I found it fails in some cases because aux and epsilon symbols removal tools introduce non-determinism. To give you an idea how the output of the program looks like here are the training graph alignments for a utterance at monophone training passes 0 and 10 (click on the picture below if you you have a modern browser supporting SVG graphics (i.e. not IE8)):

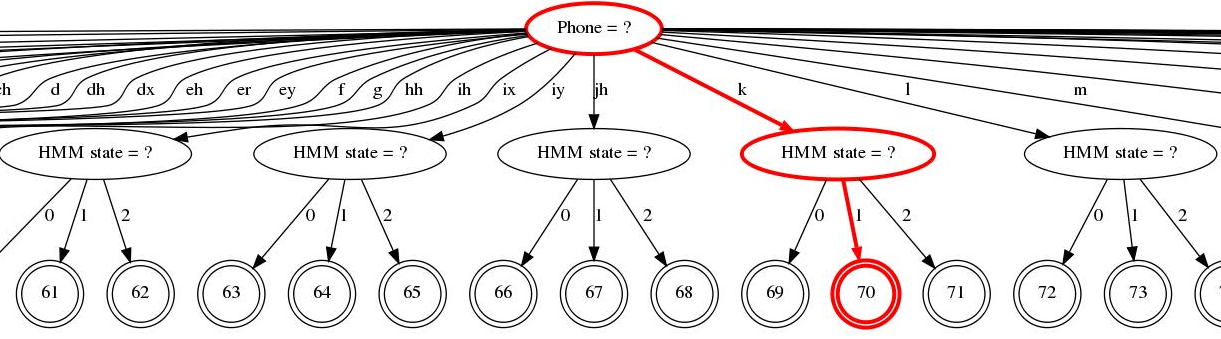
Another somewhat similar tool is draw-tree, which can be used to produce GraphViz-based pictures of the trees used for HMM state tying, and also a colored 'trace' through this tree to show how a particular HMM state is mapped to PDF. This is the only somewhat intrusive tool in the sense it requires a new method to be added to EventMap interface and its descendants in order to make tree traversal possible. Click on the picture below to view (warning: these pictures, especially the context-dependent one, are even more unwieldy than the previous ones):
The URL for the LDC metadata is now
https://catalog.ldc.upenn.edu/docs/LDC93S3B/
Thanks Toby for the blog.
The catalogs that we download is saved under docs .. so we can use mv docs/LDC93S3B ./ instead of Catalog/docs/LDC93S3B
also when I ran run.sh under data_prep, it is asking me to check "Check your RM1_ROOT" it also points out to subdirectories rm1_audio1, rm1_audio2, rm2_audio
I do not have those subdirectories that contain rm1_audio1*...
any suggestions?
Hello,
I have been browsing online a few hours today, yet I never found any interesting site like yours. It is pretty cool
I owned website about cool gadgets and products as well. It is micro site.
I would love to get your feedback
https://vipgearz.com
Cheers,
John
Hello,
I have been browsing online a few hours today, yet I never found any interesting site like yours. It is pretty cool
I owned website about cool gadgets and products as well. It is micro site.
I would love to get your feedback
Cool Gadgets
Cheers,
John